
Hyunsu Kim
Research engineer at NAVER LABS
gustnxodjs@gmail.com
About
I am a 3D computer vision research engineer on the Spatial AI team at NAVER LABS, where I turn real-world captures into detailed,
large-scale 3D reconstructions of actual places. I work across the full pipeline — squeezing every bit
of quality and scale out of 3D reconstruction (Gaussian Splatting) on raw, in-the-wild data, then refining
the result with generative models. What drives me most is owning this path end to end, from raw captures to
high-quality 3D.
Previously, I worked as a software engineer (ML R&D) on the XR team at Ohouse, specializing in 3D
vision and generative models. I played a key role in developing AR solutions such as the 'Space
Saving' and 'Furniture Removal' features, which enable users to visualize their space with accurately scaled 3D
models and experiment with virtual furniture placements. I worked closely with Hyowon Ha and Jaeheung Surh to enhance user experiences in
extended reality.
Before that, I was a research scientist on the generation research team at NAVER AI Lab, collaborating
with
Junho Kim,
Gayoung Lee, and
Yunjey Choi, as well as Prof. Jun-Yan Zhu (CMU).
I received my B.S. and M.S degrees in Computer Science and Engineering from Seoul National University in 2019 and
2021, respectively, where I was advised by Prof. Sungjoo Yoo during my Master’s program.
Projects in Ohouse: "Space Saving" & "Furniture Removal"
When purchasing furniture, do you wonder if it will match your space or if the size is right? Try out these new features!
✨ "Space Saving" Feature:
Capture your space, and it will be converted into a 3D model with accurate dimensions. You can virtually place new furniture to see how it fits.
✨ "Furniture Removal" Feature:
Remove existing furniture virtually without physically moving it and visualize your space with new furniture in place.
📹 Capture:
🚀 Demo:
Publications
Most recent publications on Google
Scholar.
‡ indicates equal contribution.

InSpace: Structure-Aware 3D Indoor Scene Generation from a Single 360° Image
Gwanhyeong Koo, Hyunsu Kim, Youngji Kim, Taejae Lee, Siwoo Lim, Sunjae Yoon, Suyong Yeon‡, Chang D. Yoo‡
ECCV, 2026

GLINT: Modeling Scene-Scale Transparency via Gaussian Radiance Transport
Youngju Na, Jaeseong Yun, Soohyun Ryu, Hyunsu Kim, Sung-Eui Yoon, Suyong Yeon
CVPR, 2026 (Oral, Award Candidate)
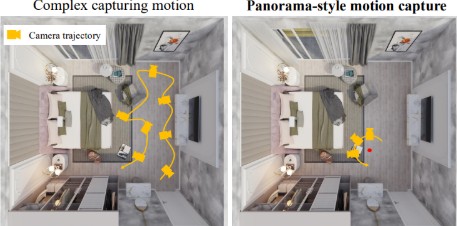
LighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Seungoh Han, Jaehoon Jang, Hyunsu Kim, Jaeheung Surh, Hyowon Ha‡, Kyungdon Joo‡
WACV, 2026

3D-aware Blending with Generative NeRFs
Hyunsu Kim, Gayoung Lee, Yunjey Choi, Jin-Hwa Kim, Jun-Yan Zhu
ICCV, 2023

BallGAN: 3D-aware Image Synthesis with a Spherical Background
Minjung Shin, Yunji Seo, Jeongmin Bae, Young Sun Choi, Hyunsu Kim, Hyeran Byun, Youngjung Uh
ICCV, 2023

Diffusion Models with Grouped Latents for Interpretable Latent Space
Sangyun Lee, Gayoung Lee, Hyunsu Kim, Junho Kim, Youngjung Uh
ICMLW, 2023
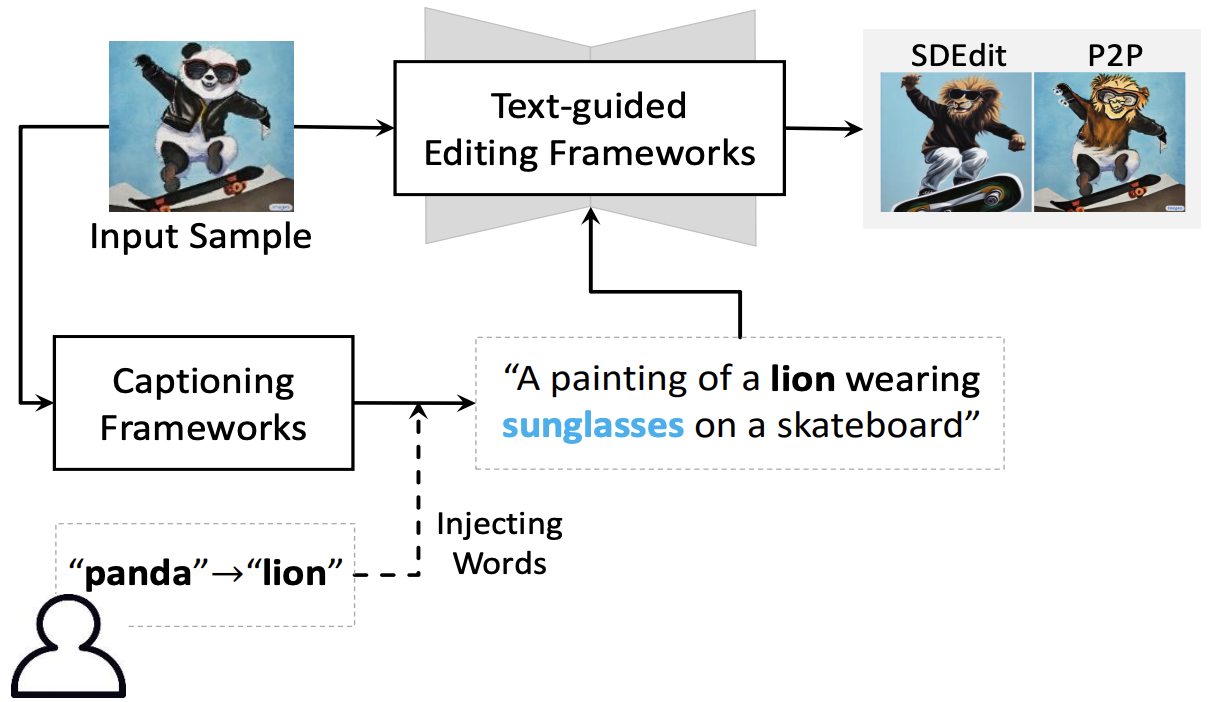
User-friendly Image Editing with Minimal Text Input: Leveraging Captioning and Injection Techniques
Sunwoo Kim, Wooseok Jang, Hyunsu Kim, Junho Kim, Yunjey Choi, Seungryong Kim, Gayeong Lee
arXiv, 2023

Diffusion Video Autoencoders: Toward Temporally Consistent Face Video Editing via Disentangled Video Encoding
Gyeongman Kim, Hajin Shim, Hyunsu Kim, Yunjey Choi, Junho Kim, Eunho Yang
CVPR, 2023

Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
Doyeon Kim, Eunji Ko, Hyunsu Kim, Yunji Kim, Junho Kim, Dongchan Min, Junmo Kim, Sung Ju Hwang
CVPRW, 2023
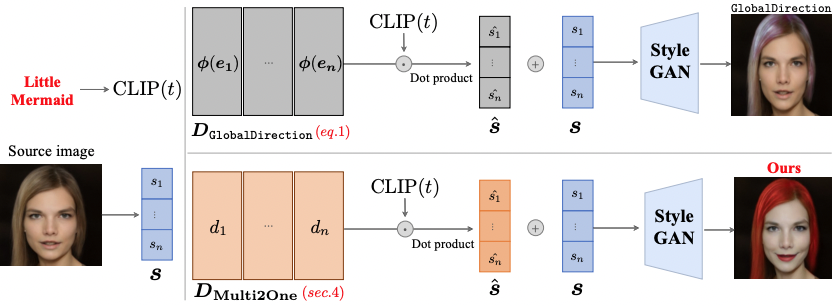
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Yoonjeon Kim, Hyunsu Kim, Junho Kim, Yunjey Choi, Eunho Yang
ICLR 2023
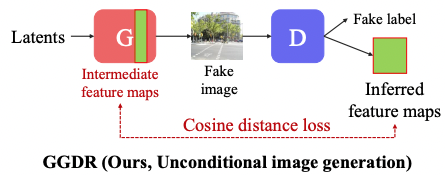
Generator Knows What Discriminator Should Learn in Unconditional GANs
Gayoung Lee, Hyunsu Kim, Junho Kim, Seonghyeon Kim, Jung-Woo Ha, Yunjey Choi
ECCV 2022
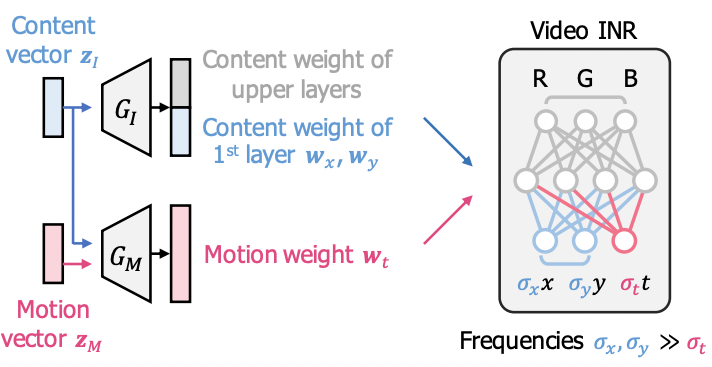
Generating videos with dynamics-aware implicit generative adversarial networks
Sihyun Yu‡, Jihoon Tack‡, Sangwoo Mo‡, Hyunsu Kim, Junho Kim, Jung-Woo Ha, Jinwoo Shin
ICLR 2022

StyleMapGAN: Exploiting Spatial Dimensions of Latent in GAN for Real-time Image Editing
Hyunsu Kim, Yunjey Choi, Junho Kim, Sungjoo Yoo, Youngjung Uh
CVPR 2021

Tag2pix: Line art colorization using text tag with secat and changing loss
Hyunsu Kim‡, Ho Young Jhoo‡, Eunhyeok Park, Sungjoo Yoo
ICCV 2019
Vitæ
-
NAVER LABS Jun 2025 – nowResearch engineer
Spatial AI -
Ohouse Oct 2023 – May 2025Software engineer
XR (extended reality) -
NAVER AI Lab Jan 2021 – Oct 2023Research Scientist
Generation Research -
NAVER AI Lab Dec 2019 – Sep 2020Research Scientist, Intern
Generation Research -
Seoul National University Mar 2019 – Feb 2021M.S. Student
Computer Science and Engineering
Under the supervision of Prof. Sungjoo Yoo. -
JP Brothers May 2017 – Nov 2017Server Engineer
Candy Camera (Installs 100,000,000+) -
CodeWings Dec 2015 – Mar 2017CEO
P2P video call service for programming education. -
Seoul National University 2013 - 2019B.S. Student
Computer Science and Engineering